
In the fast-evolving world of artificial intelligence, foundational tools like vector databases and embedding models are increasingly shaping the way we build intelligent, responsive, and context-aware applications. Whether you’re creating semantic search engines, AI chatbots that understand documents, or sophisticated RAG (retrieval-augmented generation) pipelines, these technologies work together to form the backbone of your AI-powered infrastructure. In this post, we’ll unpack what each of these tools does, how they interact, and which tools are best suited for various real-world use cases.
What is a Vector Database?
A vector database is a specialized type of data storage engine that excels at managing high-dimensional vector data—mathematical representations of unstructured inputs like text, images, and audio. These databases are optimized for approximate nearest neighbor (ANN) search, enabling fast and scalable similarity-based retrieval. Instead of searching by keywords or relational fields, vector databases allow you to search by meaning.
Here’s how it works:
- You give it vectors, and it stores them in optimized data structures.
- Later, you pass in a new vector (like a user question), and it finds the closest matches based on distance metrics like cosine similarity or Euclidean distance.
- It doesn’t interpret meaning directly; its power comes from fast vector math and search efficiency.
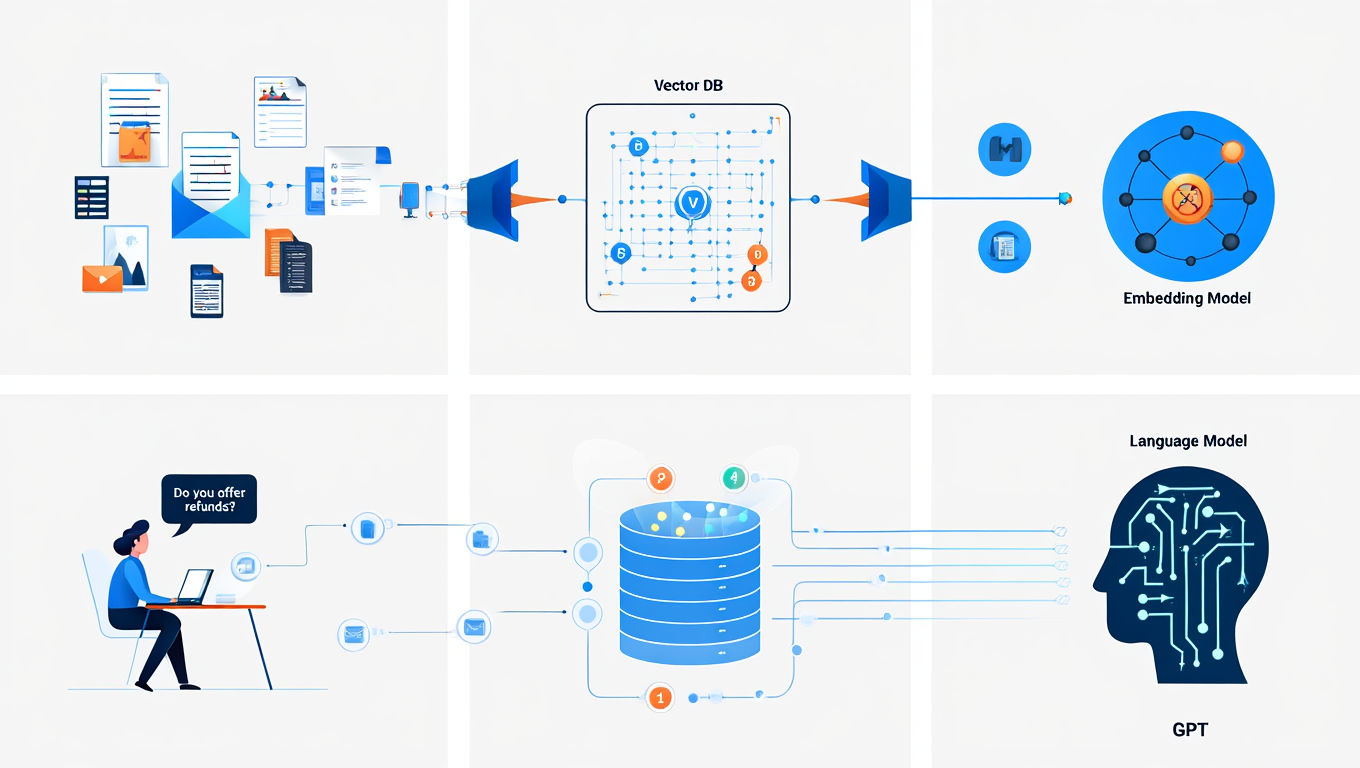 The database is just the storage and search engine. It doesn’t know how to convert human input like “How do I reset my password?” into a vector. That’s the job of an embedding model.
The database is just the storage and search engine. It doesn’t know how to convert human input like “How do I reset my password?” into a vector. That’s the job of an embedding model.
What is an Embedding Model?
An embedding model is a machine learning model trained to convert human-readable data—text, audio, images—into dense, fixed-length vectors. These vectors live in a high-dimensional space, where their position reflects the semantic meaning of the input. Embedding models are trained so that similar meanings are mapped to nearby vectors, while unrelated content ends up far apart.
For example:
- Input: “What is your refund policy?”
- Output:
[0.12, -0.98, ..., 0.33]— a 768-dimensional vector that represents the semantic meaning of that sentence.
These embeddings are used not only for search, but also for classification, clustering, recommendation engines, and more. Models are trained using techniques like contrastive learning or triplet loss, which refine the vector space over millions or billions of examples.
When Is the Embedding Model Used
The embedding model is used in two critical phases:
1. During Indexing (Storing Data)
- Documents (PDFs, websites, support articles) are split into small, manageable text chunks.
- Each chunk is passed through the embedding model to get a vector.
- These vectors are stored in the vector database.
This is often a one-time or batch process. If the document changes, you’ll need to regenerate and re-index its embeddings.
2. During Query Time (Every Search)
- A user submits a query like “Do you offer refunds?”
- The query is passed through the same embedding model to convert it to a vector.
- That query vector is compared against the database to retrieve the most relevant chunks.
This is how AI systems find context to generate intelligent, personalized responses. Matching happens at the vector level—not keyword level.
How the Full Pipeline Works (Example: Chat with PDF)
Let’s walk through a typical use case: you want to build a Chat with PDF feature that allows users to ask questions about the contents of a document.
- You upload a PDF and break it into small chunks of text.
- Each chunk is converted into a vector using an embedding model.
- The vectors are stored in a vector database (like Pinecone or Qdrant).
- A user asks a question in natural language.
- The question is embedded into a vector using the same model.
- The vector database finds the most similar chunks.
- Those chunks are passed into a large language model (like GPT) along with the question.
- The LLM generates a natural-language response based on both the query and the retrieved context.
The result: a chat interface that feels intelligent and responsive, powered entirely by embedding similarity and vector retrieval.
Embedding Models (Updated for 2025)
Here are some of the most powerful and production-ready embedding models available today:
-
OpenAI
text-embedding-3-small&3-large3-smalloffers fast, accurate embeddings at a cost 5× lower than previous models.3-largedelivers superior accuracy across multilingual and domain-specific use cases. It supports vectors up to 3072 dimensions.
-
Gemini Embeddings (by Google)
- Multilingual support for over 250 languages. Ranked at the top on MMTEB benchmarks.
-
Qwen3 Embedding Models (Alibaba)
- Open-source, multilingual models available in multiple sizes (0.6B to 8B parameters). These models perform exceptionally well on the MTEB leaderboard (score: 70.58).
-
Other Top Open-Source Models:
- BAAI bge-en-icl – consistently high performance across multiple benchmarks.
- NVIDIA NV‑Embed‑v2 – optimized for performance and speed, excellent MTEB scores.
- Microsoft E5 – strong multilingual performance in a small footprint.
💡 Advice: Use OpenAI or Gemini if you want plug-and-play performance. If you’re building something cost-conscious or self-hosted, go with BGE, Qwen3, or NV-Embed.
Curious how this fits into full agent pipelines? Check out our From Workflows to AI Agents article.
Vector Databases: Latest Players and Free Tiers
Here’s a side-by-side look at the top options for vector storage and search:
| Vector DB | Type | Free Tier | Ideal Use Cases |
|---|---|---|---|
| Pinecone | Managed cloud | ~5M vectors | High-scale RAG, blazing-fast search |
| Weaviate | OSS + Cloud Hosting | ~25k vectors | Semantic + keyword search, GraphQL API support |
| Qdrant | OSS + Managed Cloud | ~10k vectors | Fast filtering, REST and gRPC APIs, open-core architecture |
| Chroma | Fully Open-Source | Self-hosted | Lightweight, ideal for local development and testing |
| Milvus | Open-source + Cloud Option | Self-hosted | Enterprise workloads, billions of vectors |
| Supabase (pgvector) | PostgreSQL plugin | Based on DB size | SQL + vector in one stack, perfect for hybrid apps |
| Redis (RedisSearch) | In-memory plugin | Memory-limited free tier | Ultra-fast performance, ideal if Redis is already in use |
| Typesense | Lightweight OSS | Self-hosted | Hybrid text + vector search, minimal infra |
| MongoDB Atlas | Cloud DB with vector support | Part of free tier | Document-oriented apps with embedded vector use |
🧠 Bonus Tip: Use FAISS or Annoy for custom offline similarity search engines when local compute is preferred over cloud.
Recommendations Based on Stage and Use Case
Getting Started or Prototyping
- Embedding: OpenAI
3-small, MiniLM, or E5. - Vector DB: Qdrant Cloud, Supabase (pgvector), or Chroma (local).
Scaling to Production
- Embedding: OpenAI
3-large, Gemini, or Qwen3. - Vector DB: Pinecone, Weaviate, or self-hosted Milvus.
Final Thoughts
To summarize:
- Vector Databases = AI memory
- Embedding Models = Semantic brain
These components form the basis for intelligent search, document understanding, customer service automation, and virtually all RAG pipelines in production today.
Want to build something with this stack? At BrownMind, we specialize in helping teams architect, integrate, and scale AI-powered workflows that actually solve business problems—not just demo well.
Key Citations
- Choosing the Right Vector Embedding Model for Your Generative AI Use Case – DataRobot
- An Intuitive Introduction to Text Embeddings – Stack Overflow Blog
- Best Embedding Models for Information Retrieval in 2025 – DataStax
- What Are Embeddings and Vector Databases – Hugging Face Blog
- Vector Databases 2025 – Everything You Really Need to Know – det.life
- A Visual Introduction to Vector Embeddings – Microsoft Tech Blog
- Explore more blogs from Brown Mind
- Learn about our approach: Model Context Protocol (MCP)